
When thinking about theme parks, one of the most obvious questions is how to predict the number of visitors expected for the coming years. This is not easy to do, but even an approximate answer would help in planning ride maintenance and staffing levels.
Why is this so difficult?
There are a bunch of reasons it’s difficult to predict visitor numbers to any large attraction.
First, all theme parks around the world are subject to global economics – if a park attracts lots of visitors from an area that happens to have a war or a recession then all bets are off.
Second, in places like Orlando where there is a high concentration of parks the number of visitors at a specific park depends heavily on the popularity of other parks in the area.
Finally, when we are talking about a global audience, there are any number of issues that can arise that destroy a park’s precious season. In 2010 when Icelandic Volcano Eyjafjallajökull erupted unexpectedly, Danish park Tivoli Gardens saw a drop of 20,000 visitors.
How is it done?
When forecasting pretty much anything, the go-to method is called the Holt-Winters model. There is a whole lot of clever maths behind this, but what you need to know is that it looks at data collected over time (annually in our case), placing more importance on values it saw more recently than on the ones it saw a long time ago.
The data come from the Themed Entertainment Association annual reports, which are sort of canonical for the theme park industry. In this set we go back as far as their published reports allow – to 2006. This isn’t a particularly long time, especially considering that all we get is annual data, but at least we might be able to get some idea of what we could expect.
Who cares?
We have data for the top 22 or so parks for that time (the bottom few tend to drop off every couple of years), but to show what we’re doing we’ll just look at the two major competitors in the theme park industry – Disney’s Magic Kingdom, and the first non-Disney competitor Universal Studios Florida. This is interesting because Universal has recently announced an aggressive new strategy, likely based on the success of its recent Harry Potter attractions. But can Universal expect its rise to continue, or will Magic Kingdom maintain it’s unbeatable position?
The results
Well, it doesn’t look particularly good for Universal’s strategy. Here are plots of Holt-Winter’s fitting of visitor numbers to the Magic Kingdom and Universal Studios:
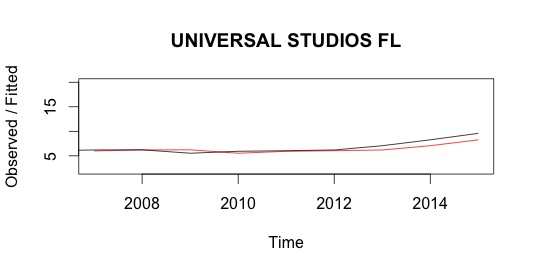

We can see that both parks are steady, but Universal Studios performs massively below Magic Kingdom. The redline shows the fitted Holt-Winters model, and to be honest I’m not that happy with it. Really we’re just predicting the value from the previous year, so I’m interested to see how it does with forecasting.
To see how the two parks might do against each other into the future, we use the Holt-Winters model to predict the next ten years of visitors:


We can see here that our (dumb) Holt-Winters model is predicting the Magic Kingdom to sustain its massive lead over Universal Studios. We can see this in the 80% confidence intervals for both parks at the ten year period – between 7 and 12.16 million visitors for Universal, and between 18.5 and 22.4 million for the Magic Kingdom. This isn’t even close to an overlap, and suggests that Universal has next to no chance of overtaking the Disney powerhouse.
The lessons
The main thing I learned from this exercise is that the Holt-Winters model is best suited to data that is more frequent than annual. The power of the model comes from estimating seasonal variations, so with monthly or even quarterly data our predictions would become a lot more interesting.
I also learned that Universal Studios may have been a little excitable by their recent success. It’s been many years since they were able to crack the Disney fortress of top ranks, and the Harry Potter world attraction seems to have had a bigger effect than they realise even at this point.
Future stuff
There is is whole lot more I’m intending to do with this data. Most immediately I’d like to be able to try and improve my forecasts by adding in information about the parks, such as their location. As I mentioned at the top of the article, the success of parks in places like Orlando and arguably the Benelux region are highly dependent on the performance of their competitors, so a model would likely be able to gain a lot of information from the performance of nearby parks.
I also want to see if there are groupings of parks according to their visitor numbers over time. Seeing different clusters of parks by this metric would suggest they are catering to different populations, and might indicate which parks were truly competing against each other.
This was fun to do, and a great experience to play around with some time series data. Hope you learned something!
